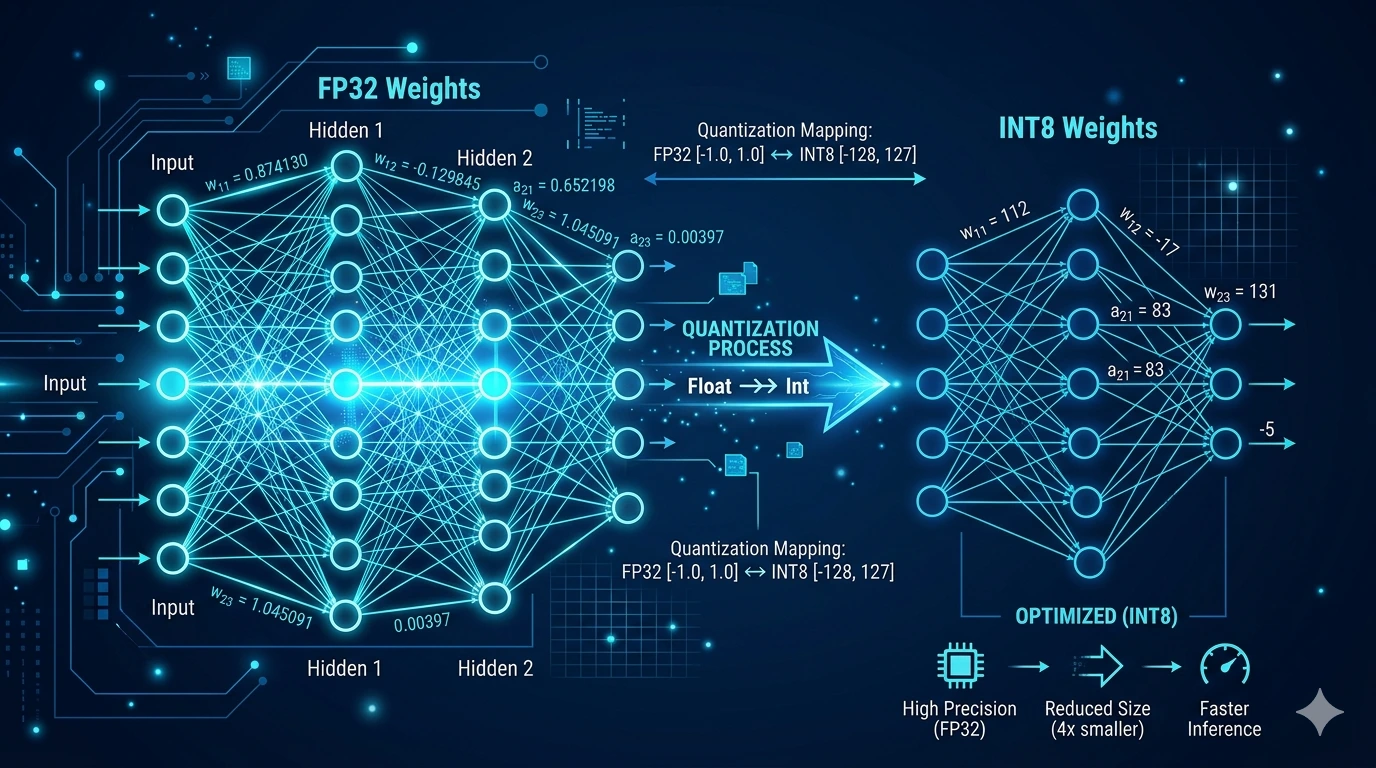
Qu’est-ce qu’un modèle quantifié ?
Si vous avez déjà vu des modèles d’IA avant installation, vous avez certainement croisé quelque chose comme : « mistral-7b-instruct-v0.3.Q4_K_M.gguf ». Le nom du modèle vous dit peut-être quelque chose, nous avons déjà écrit sur la signification de la lettre « b » après le premier chiffre – mais que veut dire cette combinaison de lettres et de chiffres à la fin ?
En fait, c’est la quantification. Une technique simple mais ingénieuse qui permet à un modèle d’IA sérieux de fonctionner sur un ordinateur de bureau ordinaire — sans perte de qualité significative.
L’essentiel en une phrase
Les modèles d’IA nécessitent à l’origine une énorme quantité de mémoire. La quantification réduit cette empreinte mémoire en stockant les « poids » internes du modèle (ses valeurs numériques) avec moins de bits, donc avec une précision légèrement réduite, mais avec une perte de qualité acceptable.
Imaginez cela comme la compression d’une photo : on passe d’un original 48 mégapixels a une version 12 mégapixels. A l’impression, la différence est imperceptible — mais le fichier est quatre fois plus léger.
Pourquoi est-ce nécessaire ?
Un modèle de 7 milliards de paramètres nécessite dans sa forme originale environ 28 Go de mémoire. Un ordinateur de bureau classique ne peut pas le faire tourner. Avec une quantification Q4, ce même modèle tient dans ~4,5 Go et peut fonctionner correctement sur un ordinateur avec seulement 8 Go de RAM.
C’est pourquoi ArkeoAI utilise par défaut des modèles Q4_K_M ou Q5_K_M : la qualité est suffisante pour les taches professionnelles du quotidien, et les exigences matériel restent réalistes.
Les formats et leur signification
Les niveaux de quantification les plus courants — de la meilleure qualite vers la plus compresse :
| Format | Taille | Qualite | RAM requise | Remarque |
| Q8_0 | ~7-8 Go | Excellente | 12+ Go | Quasi parfaite |
| Q5_K_M | ~5 Go | Tres bonne | 8 Go | Recommandé ✓ |
| Q4_K_M | ~4,5 Go | Bonne | 8 Go | Le plus répandu ✓ |
| Q3_K_M | ~3,5 Go | Moyenne | 6 Go | En dernier recours |
| Q2_K | ~2,7 Go | Faible | 4 Go | Déconseillé |
A quoi ressemble concrètement une donnée quantifiée ?
C’est une question légitime, rarement bien expliquée. Voici un exemple concret : imaginez que l’une des valeurs internes (« poids ») du modèle contient a l’origine ce nombre décimal :
0.48291763
La quantification « simplifie » cette valeur — de façon de plus en plus grossière selon le niveau de compression :
| Format | Valeur stockée | Ce que cela signifie |
| Original (FP32) | 0.48291763 | Nombre décimal précis |
| FP16 (16 bits) | 0.4829 | Légère approximation, imperceptible |
| Q8 (8 bits) | 123 | Nombre entier sur une échelle (ex. 0-255) |
| Q4 (4 bits) | 7 | Nombre entier sur une échelle (ex. 0-15) |
| Q2 (2 bits) | 2 | Seulement 4 valeurs possibles (0-3) |
Important : ces valeurs sont incompréhensibles isolément. Un modèle d’IA est composé de milliards de tels nombres qui, ensemble, forment la « connaissance » du modèle. Un seul chiffre extrait ne signifie rien, comme une seule lettre tirée d’un livre.
Ces données permettent-elles de retrouver des informations sensibles ?
C’est la question que tout utilisateur soucieux de la protection des données se pose — et elle est particulièrement importante dans le contexte d’ArkeoAI.
La réponse courte : non.
Les valeurs stockées dans le modèle quantifie (comme le 0.48… → 7 ci-dessus) proviennent du processus d’apprentissage du modèle — pas de vos documents. Vos dossiers n’entrent jamais dans le modèle ; celui-ci généralise a partir des textes vus lors de son entrainement, il ne les copie pas.
Vos documents sont stockes dans ArkeoAI dans une base de données séparée (système RAG), que le modèle interroge mais dans laquelle il n’écrit rien. Cette base reste sur l’ordinateur, sans connexion internet, sous votre contrôle.
En d’autres termes : le fichier du modèle quantifie (.gguf) ne contient rien concernant vos clients, vos contrats ou votre correspondance. Ces données restent sur la machine, le modèle n’est qu’un « outil » qu’on interroge.
En résumé
La quantification est simplement une technique de compression : les valeurs internes de l’IA sont stockées avec une précision réduite pour que le modèle fonctionne sur du matériel plus modeste. La perte de qualité est minimale pour les taches bureautiques.
- Q4_K_M et Q5_K_M : le meilleur équilibre qualité / exigences matériel
- Un modèle 7B en Q4 pèse ~4,5 Go — contre ~28 Go a l’origine
- Vos documents n’entrent pas dans le modèle et ne peuvent pas en être extraits
- ArkeoAI fonctionne hors ligne : vos données ne quittent jamais la machine