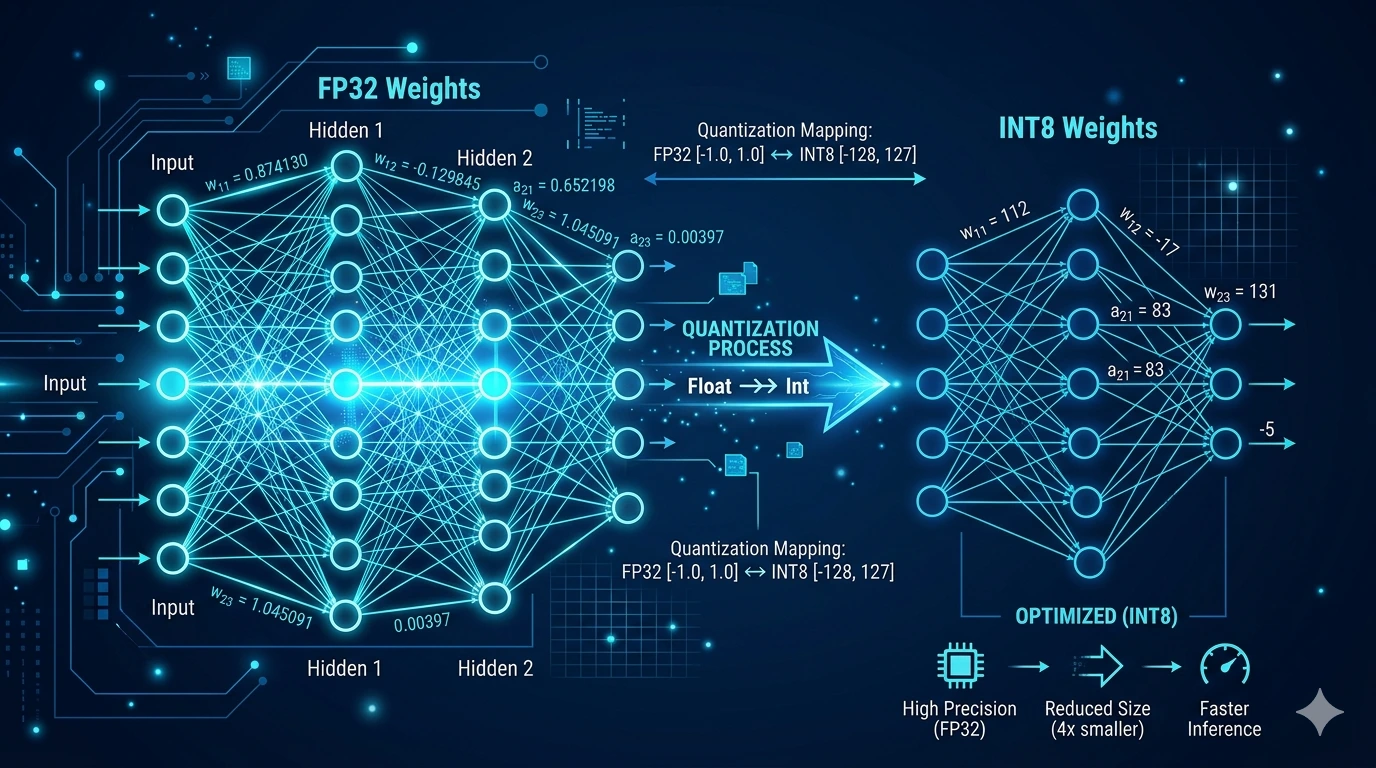
Mi az a kvantált modell?
Ha esetleg valaha látott AI-modelleket telepítés előtt, találkozhatott ilyesmivel: mistral-7b-instruct-v0.3.Q4_K_M.gguf. A modell neve talán ismerős, a “b” jelentéséről már írtunk is korábban, de mi az a betű-szám kombináció a végén?…
Nos ez a kvantálást jelöli. Egy egyszerű, de okos technika, amely lehetővé teszi, hogy egy komoly AI-modell elférjen egy normál irodai számítógépen, anélkül, hogy lényegesen gyengébb lenne.
A lényeg egy mondatban
Az AI-modellek eredetileg hatalmas mennyiségű memóriát igényelnek. A kvantálás ezt a memóriaigényt csökkenti úgy, hogy a modell „súlyait” (belső értékeit) kevesebb biten tárolja, kisebb pontossággal, de elfogadható minőségveszteséggel.
Gondoljon erre úgy, mint egy fénykép tömörítésére: a 48 megapixeles eredeti helyett 12 megapixeles verziót használunk. Nyomtatva alig látszik a különbség, de a fájl negyedakkora.
Miért kell ez egyáltalán?
Egy 7 milliárd paraméteres modell eredeti formájában ~28 GB memóriát igényelne. Ez egy átlagos irodai számítógépen nem fut. Q4 kvantálással ugyanez a modell ~4,5 GB-ba fér és akár már egy 8 GB RAM-os gépen is működik.
Az ArkeoAI ezért használ alapértelmezetten Q4_K_M vagy Q5_K_M modelleket: a minőség megfelelő a mindennapi szakmai feladatokhoz, a hardverigény pedig reális.
A formátumok és mit jelentenek
A leggyakoribb kvantálási szintek — a legjobb minőségtől a legtömörítettebb felé haladva:
| Formátum | Méret | Minőség | RAM igény | Megjegyzés |
| Q8_0 | ~7–8 GB | Kiváló | 12+ GB | Majdnem tökéletes |
| Q5_K_M | ~5 GB | Nagyon jó | 8 GB | Ajánlott ✓ |
| Q4_K_M | ~4,5 GB | Jó | 8 GB | Legelterjedtebb ✓ |
| Q3_K_M | ~3,5 GB | Közepes | 6 GB | Csak szükség esetén |
| Q2_K | ~2,7 GB | Gyenge | 4 GB | Nem ajánlott |
Konkrétan hogyan néz ki egy kvantált adat?
Ez a kérdés jogos, és ritkán kapja meg a választ. Íme egy szemléletes példa: képzelje el, hogy az AI egyik belső értéke („súlya”) eredetileg ezt a decimális számot tartalmazza:
0.48291763
A kvantálás ezt az értéket „leegyszerűsíti”, egyre durvábban, minél erősebb a tömörítés:
| Formátum | Tárolt érték | Mit jelent? |
| Eredeti (FP32) | 0.48291763 | Pontos szám |
| FP16 (16 bit) | 0.4829 | Kis kerekítés, alig észrevehető |
| Q8 (8 bit) | 123 | Egész szám egy skálán (pl. 0–255) |
| Q4 (4 bit) | 7 | Egész szám egy skálán (pl. 0–15) |
| Q2 (2 bit) | 2 | Csak 4 lehetséges érték (0–3) |
Fontos: ezek az értékek önmagukban semmit sem mondanak. Egy AI-modell milliárdnyi ilyen számból áll, és ezek együttesen alkotják a modell „tudását”. Egyetlen szám kiemelve értelmezhetetlen – mint egy könyv egyetlen betűje.
Visszanyerhető-e belőle érzékeny tartalom?
Ez az a kérdés, amely minden adatvédelmi szempontból tudatos felhasználóban fel kell, hogy merüljön és az ArkeoAI szempontjából különösen fontos.
A rövid válasz: nem.
A kvantált modellben tárolt értékek (mint a fenti 0.48… → 7) az AI tanulási folyamatából származnak és nem az Ön dokumentumaiból. Az Ön iratai soha nem kerülnek a modellbe; a modell a tanítása során látott szövegekből általánosít, nem másol.
Az Ön dokumentumai az ArkeoAI rendszerben egy külön adatbázisban vannak (RAG-rendszer), amelyet a modell lekérdez, de amelybe semmit nem ír vissza. Ez az adatbázis a gépen marad, internet-kapcsolat nélkül, az Ön felügyelete alatt.
Más szóval: a kvantált modell-fájl (.gguf) nem tartalmaz semmit az Ön ügyfeleiről, szerződéseiről vagy levelezéséről. Ezek az adatok a gépen maradnak — a modell csak „eszköz”, amelyet lekérdez.
Összefoglalás
A kvantálás egyszerűen egy tömörítési technika: az AI belső értékeit kisebb pontossággal tárolja, hogy a modell kisebb hardveren is fusson. Minőségveszteség minimális az irodai feladatoknál.
- Q4_K_M és Q5_K_M: a legjobb egyensúly minőség és hardverigény között
- Egy 7B-s modell Q4-ben ~4,5 GB — szemben az eredeti ~28 GB-tal
- Az Ön dokumentumai nem kerülnek a modellbe, és nem nyerhetők vissza belőle
- Az ArkeoAI rendszer offline működik: adatai soha nem hagyják el a gépet





